
近年、人工知能(AI)に関する技術は急速に発展し、AIモデルはビジネスでも欠かせない存在となりつつあります。普及に伴って導入ハードルが下がり始めている一方で、より適切なかたちでAIモデルを構築・運用し、理想とする成果を得るためには、正しい知識を身につけることが求められます。本記事では、AIモデルの基本的な概要やメリット、種類ごとの特徴や作成手順、精度を高めるポイントなどをご紹介します。
近年、人工知能(AI)に関する技術は急速に発展し、AIモデルはビジネスでも欠かせない存在となりつつあります。普及に伴って導入ハードルが下がり始めている一方で、より適切なかたちでAIモデルを構築・運用し、理想とする成果を得るためには、正しい知識を身につけることが求められます。本記事では、AIモデルの基本的な概要やメリット、種類ごとの特徴や作成手順、精度を高めるポイントなどをご紹介します。
AIモデルとは、人工知能(AI)によって自動的にデータを解析・学習し、物事の判断や予測を行うプログラムのことです。AIがデータを解析する技術は、機械学習のアルゴリズムによって支えられています。機械学習とは、コンピューターに大量のデータを与え、それらのデータに潜むパターンを学習させることで、人の「経験から学んで物事を判断する」という行為を再現する仕組みです。
また、AIモデルは、「入力」「モデル」「出力」という3つのプロセスで構成されています。
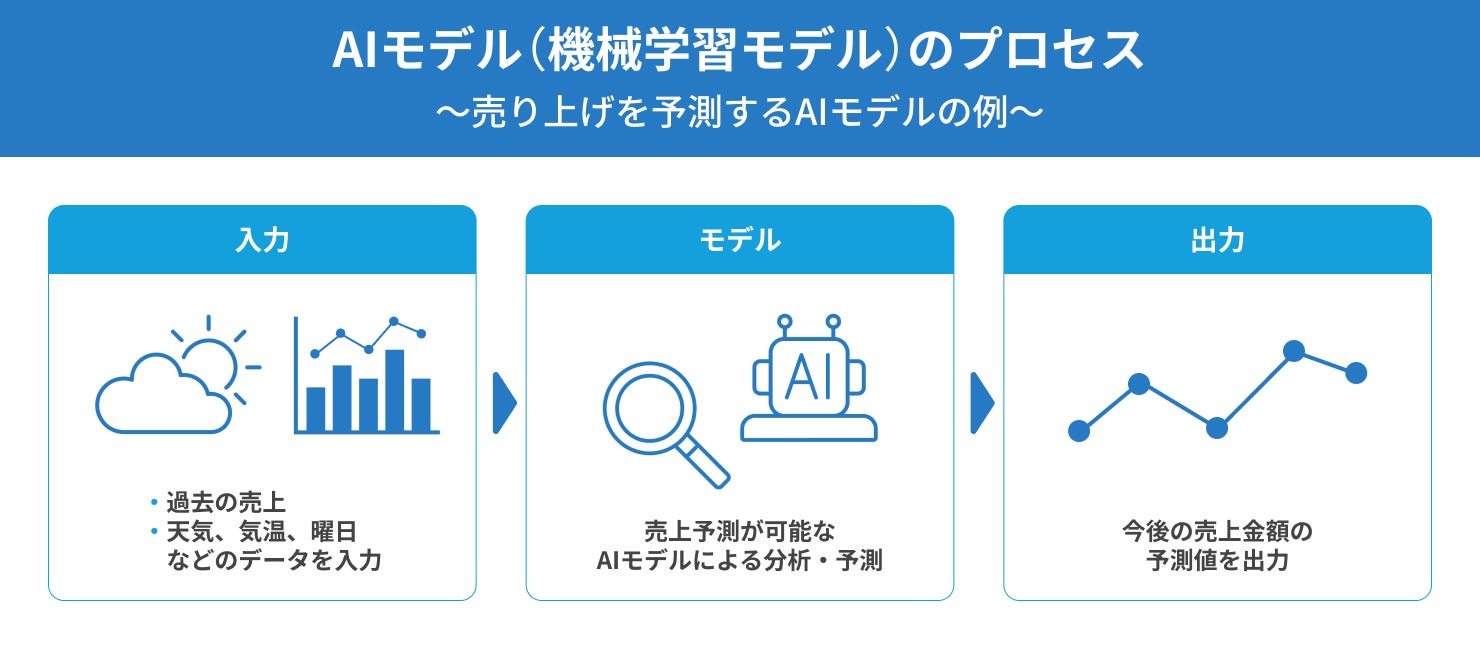
まず「入力」の段階では、判断材料となるデータをコンピューターにインプットします。人が視覚や聴覚、触覚から情報を得るように、AIはテキストや画像、音声、センサーデータといった多様な形式のデータから情報を取り込みます。売り上げ予測を行うケースであれば、データの例として過去の販売実績や天気・気温・曜日などが挙げられます。
インプットしたデータを基に、「モデル」段階で自律的にパターンを学習・分析し、最後に「モデル」で判断した結果をアウトプットする作業が「出力」です。AIモデルはこの一連の流れを繰り返すことで精度がブラッシュアップされていきます。
従来のAIモデルがデータの識別や予測を得意としていたのに対し、コンテンツの「創造」に長けているプログラムとして登場したのが、「生成AIモデル」です。
データから自律的に学習する点はどちらも共通していますが、出力するものの傾向が異なります。AIモデルは主に既存のデータから予測できる情報を出力しますが、生成AIモデルは独自のテキストや画像、動画、音声といった新たなコンテンツを生み出すことを目的としています。
AIモデルと混同されやすい言葉に「アルゴリズム」があります。アルゴリズムは目的を達成するための「手順」そのものを意味しており、プログラミング以外の分野でも使用される言葉です。 プログラミングの分野では、問題解決のための計算方法や処理手順を「アルゴリズム」と呼びます。AIモデルは、そのアルゴリズムを用いて構築されたプログラムです。また、AIモデルは人のように柔軟に物事を判別するのに対し、アルゴリズムはルールや規則に従って結果を出力します。
ビジネスにAIを活用する最大のメリットは、単に人の業務を肩代わりできるだけではなく、人の力では実現が困難な領域までサポートできる点にあります。
特に、AIモデルによる将来の予測や傾向の分析といった技術は、高度なレコメンド機能やサービスのパーソナライズ化など、これまでにない新たな付加価値を生み出すことにつながっています。
通常、こうしたサービスを実現するには、膨大なデータを高速かつ高精度に処理する必要があり、人の手で行うのは非現実的です。しかし、AIモデルであれば、容易にデータ分析を行え、業務効率の向上と新たな価値の創出を実現できます。
AIモデルにはいくつかの種類があり、それぞれ特徴があります。そのため、どれか一つですべてのケースに対応するのではなく、目的に応じて選択することが重要です。ここでは、4つのAIモデルの特徴を紹介します。
「教師あり学習」は、コンピューターに正解を教えるための「教師データ」を用意して学習を行う手法です。例えば、猫の画像に「猫」という正解ラベルをつけて読み込ませることで、AIは画像から猫の特徴を学習し、猫を判別できるようになります。
「教師あり学習モデル」は、「回帰モデル」「分類モデル」の2種類に細分化されます。
連続した数値のデータから、将来的にその数値がどう変動していくかを予測できるモデルです。売り上げや株価、金融、気象などの予測に役立ちます。手法はいくつかありますが、代表的なのは「線形回帰」と「多項式回帰」です。「線形回帰」は原因となる変数が1つのときに利用するシンプルな手法です。「多項式回帰」は、原因となる変数とそれを受けて発生した結果を指す変数を、二次関数・三次関数のような非線形の分布で表すときに使われます。
データを属性ごとに分類したいときに役立つモデルです。2つの項目のどちらかに振り分けるものを「2値分類」、項目が3つ以上あるものを「多値分類」と呼びます。異常の検出や画像診断、迷惑メールのフィルタリングなどで活用されます。
「教師なし学習」は、正解が示されていないデータで学習を行う手法です。「教師なし学習モデル」ではAIが自らデータを解析し、類似点や相違点、パターンを導き出します。
例えば、発売前の製品のターゲット市場をリサーチする場合など、未知のパターンを探る際に活用されます。AIはパターン分けを行うのみで、それが何を示すのかを理解することはできないため、最終的な判断は人が行う必要があります。
また、「教師なし学習」の主な分析手法には、「クラスタリング」と「主成分分析」があります。
データを類似度によってグループ分けする手法です。仕分けたグループは「クラスタ」と呼びます。属性や好みに応じて顧客データを分類するなど、正解のないデータの仕分けに利用されます。
大量のデータを分析しやすいように要約する統計的手法です。情報を集約してデータの特徴を表す要素(主成分)に置き換えることで、より少ない要素でデータの構造を把握でき、計算負荷の削減や分析精度の向上につながります。アンケートや評価の分析に使われるほか、AIが余分な学習をして精度が下がることを防ぎます。

「強化学習モデル」では、学習対象となるデータを与えず、AI自身がトライアンドエラーを繰り返すことで行動を最適化します。囲碁や将棋をするAIや、自動運転、ロボットの制御などに活用されるモデルです。
この手法では、AIが行動した結果に応じて報酬(スコア)を与えることで、AIに報酬を最大化できるパターンを探らせます。例えば、二足歩行をするロボットの場合、より長い距離を歩き続ければ多くの報酬が与えられるよう設定すれば、AIはいろいろな動作パターンを自ら試して、最も長距離を歩ける条件を見つけ出します。
「ディープラーニング(深層学習)モデル」は機械学習手法の一種で、従来型よりも高度な分析が行えるのが特徴です。人の脳の構造や機能を模した仕組みで、入力層と出力層の間に多層構造化された「中間層」があることで複雑な情報処理を実現します。
このため、ディープラーニングモデルは複雑なパターンでも精密な識別が可能です。また、人の手で正解へ導かなくても、自ら大量のデータを分析して特徴を学びます。テキストや画像、音声などを人の脳に近いプロセスで認識・処理できるため、画像認識や自然言語処理などの分野で特に力を発揮するモデルです。
AIモデルを自作する場合、目的に合った種類の選定や学習データの準備をし、繰り返し学習をさせることが重要です。ここでは、以下の5つのステップに沿って大まかな作成手順を解説します。
STEP1:AIモデルの活用目的を明確にする
STEP2:目的に応じて適切なデータを収集する
STEP3:収集したデータを加工する
STEP4:最適なAIモデルを選定し、構築する
STEP5:作成後は定期的に評価・再学習を行う
AIモデルは学習した内容に基づいて物事を判断するため、あらかじめ活用目的が定まっていないと、必要な情報を学習させることができません。また、前述のとおり、AIモデルには種類ごとに特徴があるため、適切な種類を選定するためにも、「自社の将来的な売り上げを予測したい」「顧客の傾向を分析して適切なマーケティングにつなげたい」といった具体的な活用目的の設定が必要です。
次に、活用目的に応じて必要な学習データを収集します。売り上げ予測が目的であれば過去の売り上げ、顧客の傾向分析が目的であれば顧客の属性や購入履歴、Webサイト内の行動履歴などが例として挙げられます。
また、AIモデルの精度は学習データの量や質に大きく左右されます。そのため、学習に悪影響となるような不正確なデータや曖昧なデータは避けるように注意しつつ、なるべく多くの量や種類を確保しておかなければなりません。目的達成に必要なデータの量や質の確保は、多大な時間とコストを要する場合があります。
量が不足している場合、一般的に配布されているデータセットを利用するのも手段の一つです。データセットは無料で配布されているもののほか、企業が有料で提供しているものもあるため、求めるデータの内容や品質を踏まえて選びます。
データを収集したら、重複や漏れ、偏りといった不備がないか確認し、問題があれば修正を行います。その後、データを学習に適した形へ加工する作業に移ります。
特に「教師あり学習モデル」のように、人の手で正解を示す必要がある場合、この段階で正解やヒントを示すための情報をデータに付与しなければなりません。この作業は「ラベル付け」や「アノテーション」と呼ばれます。「ラベル付け」では、特定の分類や属性といった明確な正解を簡潔に教えるためのラベルをつけ、「アノテーション」ではより広範囲で詳細な情報をつけ足し、AIがデータの内容を理解しやすいように手助けします。 こうした加工作業や不備の修正が適切に行われていないと、多くのデータを用意したとしても、AIが正しく学習を行えなくなってしまいます。
データの修正・加工を終えたら、実際にAIモデルを構築します。画像認識が得意なモデル、音声認識が得意なモデルなど、AIモデルそれぞれの特徴を考慮し、事前に設定した活用目的に合った種類を選択して学習を進めます。専門的な知識がない場合、プログラミング不要の開発ツールなどを利用するとスムーズに構築できます。
AIモデルの構築時には、曲線の設定値や誤差の許容範囲といったパラメータを決定するほか、モデルのトレーニングも行います。例えば、機械学習モデルの一つ「ニューラルネットワーク」に対しては、「ネットワークの重み付け」というトレーニングが行われます。これは、ニューラルネットワークの中間層において、処理する情報の重要度を指す「重み」という数値を調整する作業です。「重み付け」を行うことで、AIはどの情報を重視すべきかを学習し、より正確な判断が可能になります。
AIモデルの作成後は、作成したモデルが想定通りに機能するかどうかを確認するテストを行います。問題が発生したり、求める精度に達していなかったりする場合は、再び学習を行います。このように評価と再学習を繰り返すことで、理想の精度に近づきます。
また、一度作成が完了した後も定期的に評価・再学習を行うことが大切です。最初に作成してから期間が経過すると、環境や社会情勢の変化に伴って扱う情報に変化が起き、予測精度が下がる恐れがあるためです。定期的に再学習することで、時代の変化に順応したAIモデルに更新できます。 このような「機械学習のプロジェクトにおいて継続的な本番運用を目指す」という概念や、そのための手法のことを「MLOps」と呼びます。AIモデルを一度構築しただけで終わらせないために重要であるとして、近年注目を集めている考え方です。
実際のビジネスなどでAIモデルを活用する場合、導入する目的を達成できる精度を確保することが重要です。AIモデルの精度を高めるために気をつけるべきポイントとして、以下の3点が挙げられます。
前述したように、高精度なAIモデルを目指すには、モデルが十分に力を発揮できるよう活用目的に合った種類を選ぶことが大切です。主な種類と活用例をまとめると、以下のようになります。
| 種類 | できること | 具体的な活用例 |
|---|---|---|
| 教師あり学習モデル:回帰モデル | 将来的な数値の変化を予測 | ・売り上げ、株価の予測 ・気象予測 ・自動車検査 |
| 教師あり学習モデル:分類モデル | データを属性で分ける | ・異常値検出 ・画像診断 ・スパムフィルタ |
| 教師なし学習モデル:クラスタリング | データを類似度でグルーピングする | ・顧客セグメント分析 ・不良品のタイプ分解 ・データの自動仕分け |
| 教師なし学習モデル:主成分分析 | データを要約する | ・アンケート結果の分析 ・企業や商品の評価 ・画像補整 |
| 強化学習モデル | AI自身によるトライアンドエラー | ・囲碁、将棋AI ・自動運転 ・ロボット制御 |
| ディープラーニング(深層学習)モデル | 画像、音声、自然言語など複雑な情報を理解する | ・不良品検知 ・問い合わせ対応 ・自動翻訳 |
また、精度を向上させようとすると、コストや運用スキルが求められたり、必要なデータ量が肥大化したりと、さまざまな課題が出てきます。これらを考慮しながら、可能な範囲で精度を高められる形を模索する必要があります。
AIモデルの学習における精度の低下を防ぐには、データの偏りや学習不足、特定のデータにだけ最適化してしまう「過学習」などのほか、評価指標の選択にも気をつけなければなりません。
例えば、病気の発見に役立つ分類モデルを構築し、100人の患者を診断したとします。このうち99人が健康で1人が病気だった場合、このモデルを「正解率」だけで評価すると、粗雑に「全員健康です」と診断していたとしても、正解率99%と高い数値が出ます。しかしその場合、病気である1人を見つけられておらず、結果的に病気の発見には生かせないということになります。 しっかりと精度を向上させるためには、適切な指標で評価をすることが重要です。今回取り上げた分類モデルの例であれば、以下の表のように、「どう間違えたか」まで把握できるように整理する「混合行列」が、適切な指標として挙げられます。
| AI の予測 | |||
| 病気 (Positive) | 健康 (Negative) | ||
| 実際の値 | 病気 (Positive) | 真陽性 (True Positive) 0 人 | 偽陰性 (False Negative) 1 人 |
| 健康(Negative) | 偽陽性 (False Positive) 0 人 | 真陰性 (True Negative) 99 人 | |
AI自身が柔軟に物事を判断できるようになった一方、AIが何を根拠に物事を判断しているのかが不明瞭だと、問題が起きた際の原因究明が困難になります。特に、「ディープラーニングモデル」はその仕組み上、ブラックボックス化しやすい点が問題視されています。
そこで注目されているのが、「説明可能なAI(XAI)」という考え方です。この概念は、アメリカの国防高等研究計画局(DARPA)が発表した研究プロジェクトをきっかけに浸透したもので、AIの振る舞いについてさまざまな観点から理解し、信頼できることを目指す技術の総称です。
「説明可能なAI」の手法を導入すると、AIの判断過程の検証やデータの可視化が可能となり、開発者による機能のチェックや検証がしやすくなります。その結果、モデルを適切に改善でき、精度を向上させることができます。判断の根拠が明確になることで、AIモデルを使用するエンドユーザーの信頼につながる点もメリットといえます。
本記事では、AIモデルの概要や作り方、精度向上のポイントなどについてご紹介しました。技術の進化に伴って課題が生まれるなか、「MLOps」や「説明可能なAI」といった新たな考え方も広まるなど、AIに関連する技術や情勢は日々変化しています。
今回ご紹介した内容が、AIモデルの活用を考えている方のご参考になれば幸いです。
Sky株式会社では、AI開発や社内のAI活用、自社商品開発など幅広い業務に携わるAIエンジニアを募集しています。技術・知識を共有する企業文化や手を上げれば挑戦できる土壌が根づいており、上流工程から携われるチャンスが多くあります。業務に役立つ資格取得の支援制度も充実しており、AIエンジニアとして成長できる環境が整っています。
AIエンジニアとしてのキャリアアップや転職を考えている方は、ぜひSky株式会社への応募をご検討ください。
Sky株式会社キャリア採用サイト|AIエンジニア募集職種一覧
Sky株式会社のAIエンジニアの募集要項について、詳しくはこちらをご覧ください。