
AIの登場によって画像認識の精度は急速に高まり、スマートフォンの顔認証や紙書類のデータ化をはじめとし、身近な場所で「画像認識AI」が活用される例が増えてきました。幅広い領域での活用が見込まれる画像認識AIですが、従来の画像認識との違いや具体的な機能、開発する際の手順はどのようなものなのでしょうか。本記事では、画像認識AIの概要や特徴、種類による違い、実際に構築する方法についてご紹介します。
AIの登場によって画像認識の精度は急速に高まり、スマートフォンの顔認証や紙書類のデータ化をはじめとし、身近な場所で「画像認識AI」が活用される例が増えてきました。幅広い領域での活用が見込まれる画像認識AIですが、従来の画像認識との違いや具体的な機能、開発する際の手順はどのようなものなのでしょうか。本記事では、画像認識AIの概要や特徴、種類による違い、実際に構築する方法についてご紹介します。
画像認識AIは「パターン認識技術」の一種で、画像や映像の中にあるモノの認識・分析と、それを踏まえたさまざまな判断をコンピューターに行わせる技術です。人は目で情報を受け取る際、これまでの経験から学んできたパターンに当てはめて「目の前にあるモノは何か」を識別しています。そのため、たとえば初めて会う人でも、人間の特徴に当てはまっていれば「これは人間だ」と判断できます。
画像認識AIは、コンピューターにパターンやルールを学習させる「機械学習」の活用によって、人がパターンからモノを識別する仕組みを再現しています。近年では、コンピューターが自動的に膨大な量のデータを学習し、より複雑なパターンを発見できる「ディープラーニング(深層学習)」によって精度が向上し、幅広い分野で活用されるようになりました。
画像認識技術の原点は、1940年代に登場した「バーコード」といわれています。バーコードは、白と黒のバーをデジタル信号に置き換えることで数字や文字を読み取るシンプルな仕組みです。その後、コンピューターの普及とともに広まったのが「テンプレートマッチング」です。検出対象の画像をテンプレートとして覚えることで、それに似た物体を見つけ出して位置を特定する「画像検出」が行えるようになりました。
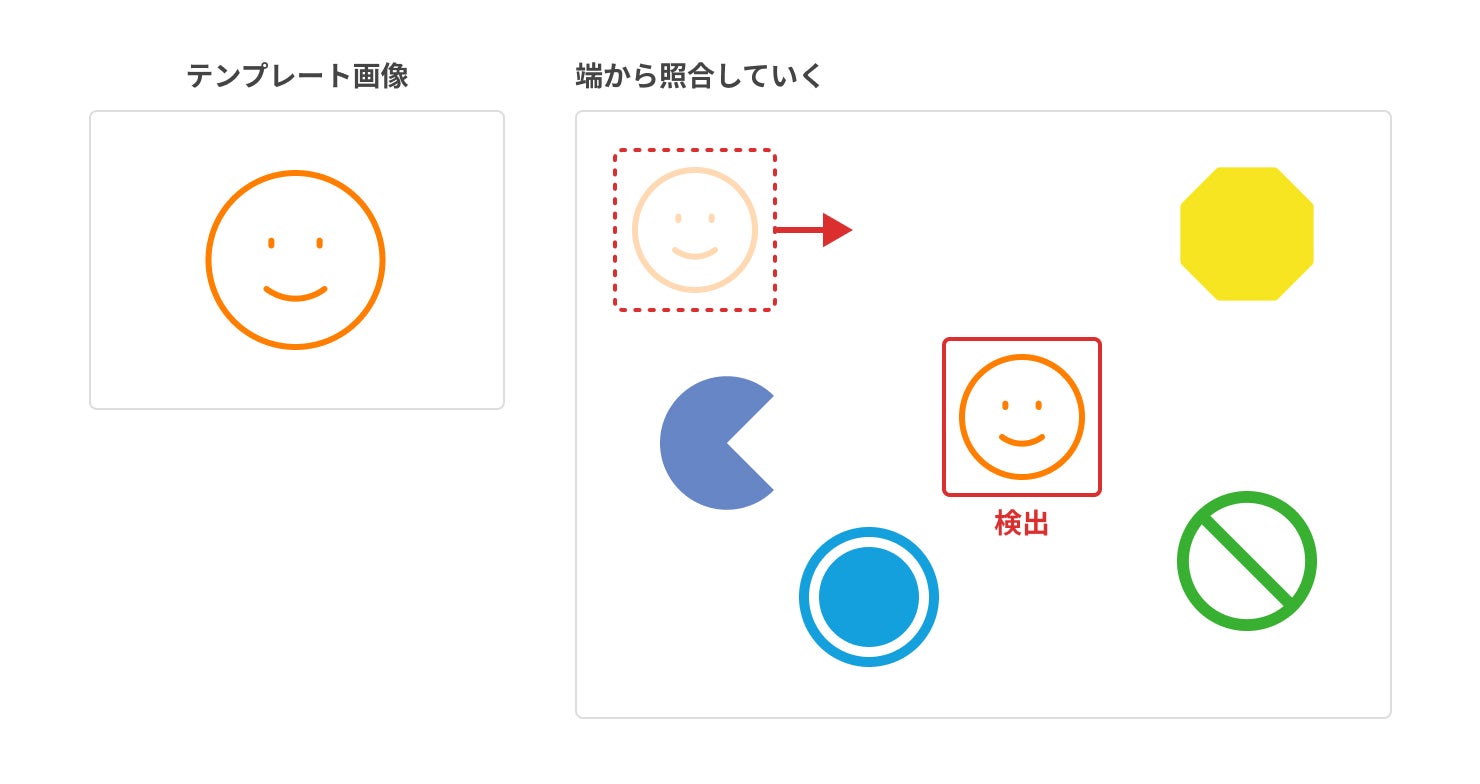
テンプレートマッチングは、2000年代以前には画像認識の代表的な手法として広まっていました。しかし、「検出対象の数だけテンプレートが必要になる」「照明の変化などにより誤認が発生しやすい」といった問題点がありました。
2000年代に入りデータ処理が高速化すると、その問題を解決できる「パターン認識」への移行が始まります。さらに2012年には、画像認識コンテストにおいて、前述したディープラーニングを活用した成功事例が登場し、注目を集めました。ディープラーニングでは、AIが膨大なデータから自動的に特徴を抽出・学習します。この技術により、画像認識の精度は飛躍的に向上しました。
さまざまな分野で活用が進む画像認識AIですが、重宝される理由は精度の高さだけではありません。以下のような特徴があることで、活躍の場が広がっています。
画像認識AIは、生産ラインにおける不良品の検出や郵便物の仕分けなど、これまでは目視で行われていた業務を自動化できます。これにより、人のコンディションに左右されることなく処理でき、ヒューマンエラーを避けられるため、業務の効率化やコスト削減に役立ちます。この特徴は、「人の流れを測定してマーケティングに活用する」「車の自動運転を行う」といった、従来は存在しなかったプロセスやビジネスモデルの確立にも貢献しています。また、学習次第で専門的な業務の効率化まで実現できる点も強みです。
ディープラーニングにはいくつかの手法がありますが、画像認識AIでは一般的に「CNN(畳み込みニューラルネットワーク)」が採用されています。CNNは画像認識に強く、複雑な画像にも対応できます。また近年、処理速度を向上させる研究結果が発表されています。画像データを高速で分析できるため、顔認証によるスマートフォンのロック解除など、スピードが求められる場面でも画像認識AIが利用されるようになっています。
画像認識AIの大きな特徴は、従来の技術と比べて認識精度が格段に向上している点です。前述したとおり、機械学習やディープラーニングが登場する以前の手法では、膨大なデータや複雑なパターンへの対応が困難でした。しかし、画像認識AIであれば、大量のデータから学習して正確に対象物を識別できます。また、AI学習ではまず汎用的なデータで基礎的な学習をしてから用途に合わせて再学習する、という二段階での学習が行われるのが一般的です。だからこそ、高精度で実用的な画像認識を実現できます。
画像認識AIのモデルは、一度パターンを学習し終えたら完成、というわけではなく、追加の学習を行うことでより精度を高められます。こうした拡張性の高さも、画像認識AIの特徴の一つです。精度を高めるために、元画像を変換したり合成したりといった幅広いバリエーションを学習させます。自動運転の障害物検出や病院での画像診断、セキュリティシステムといった幅広い分野に適応できる理由には、この拡張性の高さがあるといえます。
画像認識AIがモノを識別する仕組みにはいくつかの種類があり、扱う画像データや目的に応じて使い分けられています。ここでは、その種類と、それぞれがどのような機能を持っているのかをご紹介します。
人は画像を見た時に「どこ」に「何」があるかをほぼ同時に判断できますが、コンピューターの場合は位置などの検出と情報の識別とを別々の技術として扱います。このような情報の識別を担う技術が、物体認識です。その識別方法は、「一般物体認識」と「特定物体認識」に分けられます。前者は大枠のカテゴリーを判別するのに対し、後者はカテゴリー内の特定の種類まで細かく判別します。これらの技術は、顔認証や画像検索などの仕組みに利用されています。
物体検出では、画像内に含まれる対象物の位置を特定します。情報を抽出する上で物体の位置が重要になる場合もあるため、前述の「物体認識」と併用されるケースも多くあります。物体検出は、車の自動運転において特に欠かせない技術です。標識や白線、周囲の車両、歩行者など、安全に走行する上で必要な情報を物体検出によって把握しているためです。このほか、防犯システムで不審者を検知する場面などでも活用されています。

画像キャプション生成では、画像の中に何が写っているか、どのような状況なのかを認識し、人が理解できるキャプション(テキスト)として出力します。この手法では、画像認識の技術に加え、コンピューターに人の言葉を理解・生成させる「自然言語処理」の技術も必要です。視覚障害者向けに画像や動画の内容を説明するために活用されているほか、インターネット上にある大量の画像をラベリングし、検索エンジンに内容を理解させるための技術としての利用も見込まれています。

セグメンテーションは、画像をピクセル単位で分解し、それぞれがどの物体の領域に属しているかを識別する技術です。画像に写る物体同士の境界線を明確にして具体的な形状や位置を判定できるため、自動運転や医療現場における画像解析など、高い精度が求められる分野で活躍しています。

図のように画像全体をカテゴリーで分ける「セマンティックセグメンテーション」が代表的な手法です。このほかの手法として、物体のみを検出して個体ごとに区別する「インスタンスセグメンテーション」、背景はカテゴリーでまとめ、物体は個体ごとに区別する「パノプティックセグメンテーション」があります。
顔認識では、顔のパーツごとの位置や形といった特徴を抽出することで、人物の特定や照合を行います。識別のほか、似ている顔の検索やグループ化も可能です。スマートフォンのロック解除やセキュリティシステムなど、身近な場面でよく使われている技術です。本人確認を迅速化し、セキュリティレベルを高められる点に加え、非接触で衛生的に照合ができることから、活用が進んでいます。
文字認識(OCR)は、画像内に含まれる文字を認識し、テキストデータにする技術です。学習により、手書きの文字と印刷された文字のどちらにも対応できます。例えば、郵便物の住所読み取りや名刺管理アプリの名刺情報のデータ化、学校での手書き答案のデータ化などに利用されており、業務効率化に貢献しています。翻訳機能と組み合わせることでカメラで撮影した文字をその場で翻訳できるなど、利用用途の幅が広い技術です。
画像認識AIモデルを構築する場合、適切な手順で構築を進めることが重要です。大まかな流れは以下のとおりです。
STEP1:データ収集と画像加工を行う
STEP2:ディープラーニングモデルの設計を行う
STEP3:画像認識モデルの実装・検証を行う
STEP4:再学習と検証を繰り返す
ここでは、各ステップについて詳しく解説します。
まず、開発環境の構築や必要なライブラリのインストールといった事前準備が必要です。準備が完了したら、機械学習を行うためのデータ収集と加工を行います。画像認識AIを構築する上で、データの準備は特に重要な工程です。画像認識AIの開発では既存のデータセットが広く配布されているため、必要に応じて利用することで、効率的なモデル構築が可能になります。
また、集めた画像データには、学習させたい特徴を特定するためのラベル付け(アノテーション)を行う必要があります。高精度な画像認識AIを構築するには、量質ともに高い画像データを収集し、そこに正確なラベル付けを行うことが求められます。
データの準備を終えたら、ディープラーニングモデルを設計します。前述したように、画像認識モデルでは「CNN」を採用するのが一般的です。また、画像認識モデルにはそれぞれ得意な分野、苦手な分野があるため、目的に合ったモデルを選択することも重要です。ディープラーニングモデルの設計は、配布されているライブラリやフレームワークを利用することで、スムーズに進められます。中でも代表的な選択肢として、Googleが開発したオープンソースの深層学習フレームワーク「TensorFlow」などがあります。
ディープラーニングは、人間の脳神経系の仕組みを模した「ニューラルネットワーク」によって、複雑な情報処理を可能にしています。ニューラルネットワークはいくつかの層で構成されていますが、中でもCNNは「畳み込み層」や「プーリング層」と呼ばれる独自の構造を持っているのが特徴です。畳み込み層は画像内の局所的な特徴量を抽出する能力に優れており、プーリング層には畳み込み層で抽出された重要な情報を保持する役割があります。このような仕組みがあることから、CNNは画像認識が得意なニューラルネットワークとして知られています。
次に、用意したデータを使って画像認識モデルに学習させます。モデルが予測した結果と正解ラベルとの誤差を基にしてモデルのパラメータを調整することで、精度が向上します。モデルの構築後は、想定通りに画像の読み取りが行えるか否かを評価することが大切です。準備した画像データを事前に「学習用」と「テスト用」に分けておくことで、スムーズに検証できます。また、学習時にはモデルが学習データの内容に特化し過ぎて汎用性を失ってしまう「過学習」が起こらないよう注意しなければなりません。
検証の結果から改善点が見つかったら、データの追加や正解ラベルの修正、学習条件の再調整などを行い、再度学習させます。改善点を修正することで、より理想に近い画像認識モデルを構築できます。人が失敗しながら成長していくのと同じように、AIも試行錯誤の積み重ねによって賢くなります。そのため、画像認識モデルの精度向上を目指すには、検証と再学習の繰り返しが欠かせません。
ここまで、画像認識AIの特徴や機能、構築の手順などを解説してきました。AIの登場によって飛躍的に精度が向上し、身近な存在となりつつある画像認識の技術は、今後も活用の場が広がっていくと考えられます。画像認識AIを活用する際は、特徴や仕組みについてよく理解しておくことが大切です。本記事が、画像認識AIの利用や構築を検討している方の参考になれば幸いです。
Sky株式会社では、AIエンジニアやプログラマー職のキャリア採用を実施しています。未経験の領域もチームでサポートする体制が整っており、知識の幅を広げてステップアップを目指せる環境です。医療機器や自動運転/先進運転支援システムなど、画像認識AIとの関係が深い領域での受託開発も行っています。AIに関する知識や経験を生かせる転職先を探したい、エンジニアとしてもっと成長したいとお考えの方は、ぜひSky株式会社への応募をご検討ください。
Sky株式会社キャリア採用サイト|エンジニア募集職種一覧
Sky株式会社のエンジニアの募集要項について、詳しくはこちらをご覧ください。
Sky株式会社キャリア採用サイト|AIエンジニア募集職種一覧
Sky株式会社のAIエンジニアの募集要項について、詳しくはこちらをご覧ください。